LoRA (Low-Rank Adaptation)
LoRA는 PEFT(Parameter-Efficient Fine-Tuning) 기술 중 하나입니다.
이 기술은 대형 사전 학습 모델을 특정 작업에 맞게 효율적으로 Fine tuning 하는 방법입니다.
(다음 내용은 논문 "LoRA: Low-Rank Adaptation of Large Language Models" 를 참고하였습니다.)
-
배경/문제
LLM(Large Language Model) 같은 Model은 파라미터 수가 매우 많습니다.
예로, 24년 4월 출시된 llama3 model의 Parameter 수는 약 700억개이며 File 크기가 40GB가 넘으며, 이보다 더 큰 Model도 많습니다.
이런 Large model을 Full fine tuning 하려면 고성능 GPU가 필요하며 학습 시간도 긴 편입니다.
또한, Base model을 Full fine tuning 하는 것은 Pretraining에서 학습된 기본 성능을 저하 시킬 여지가 있습니다. -
개선
Fine tuning 학습시간을 감소시키고 Base model의 기본 성능을 저해하지 않는 기법이 LoRA입니다.
그 원리를 알아 봅시다.
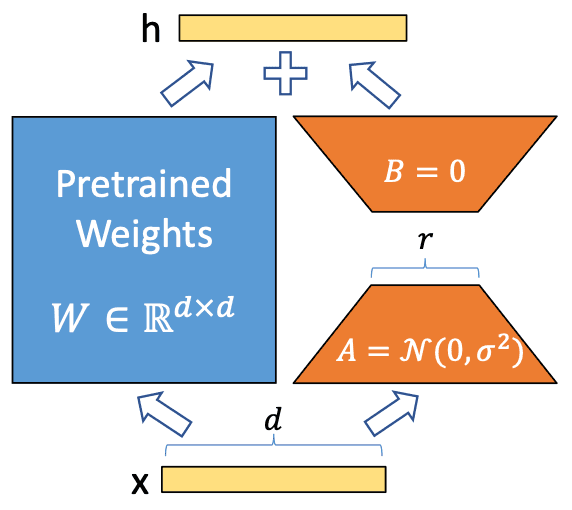
위 그림은 LoRA를 이해하기 위한 대표적인 그림이며, 각 기호의 Notation은 다음과 같습니다.
- x : 의 input (: 집합기호 실수체, 여기서는 1행d열의 Matrix라고 이해해도 됩니다.)
- h : output
- (blue color) : pretrained weights (사전학습된 파라미터)
- : 는 인 실수체 에 속함 (여기서는 d행d열의 Matrix라고 이해해도 됩니다.)
- , (orange color) : LoRA Adaptor (Fine tuning 학습되는 파라미터, LoRA의 핵심!)
- : 의 초기값은 정규분포 (Gaussian noise)
- : 의 초기값은 0
개략적인 개념을 먼저 알아봅시다.
는 Pretrained weights로 위에서 언급했던 매우 많은 파라미터이며, 이것을 Fine tuning 하는 것은 많은 비용이 필요합니다.
따라서, Adaptor라 불리는 와 를 추가 시키고 이 부분만 학습하는 것이 LoRA의 핵심입니다.
이때, 는 Freeze 하여 학습되지 않도록 하기 때문에, Base model의 기본 성능을 유지할 수 있습니다.
, 의 파라미터 수는 대비 매우 적습니다. (보통은 1% 미만)
, 는 Query, Key, Value, Output에 선택적으로 추가 시킬 수 있습니다.
이번에는 흐름을 따라가며 조금 더 자세히 알아봅시다.
Step 1.1) input x를 와 연산 --> x = =
Step 1.2) input x를 , 와 연산 --> x = =
Step 2) Step 1.1과 1.2의 결과를 더하여 h를 출력 --> + =
1.1에 1.2의 결과를 더했기 때문에, Vector space에서 embedding된 token의 위치는 1.2결과 만큼 offset을 가지고 Alignment 된 것입니다.
즉, Base model의 결과와 다르게 출력될 수 있다는 의미 입니다.
LoRA는 이런 원리로 Fine tuning 됩니다.
이번에는 임의의 숫자를 대입하여 파라미터 수가 얼마나 줄어드는지 알아봅시다.
=4096, =16 으로 가정하겠습니다.
- ()의 파라미터 수 : 4096 x 4096 = 16,777,216 개
- (), () 파라미터 수의 합 : 4096x16 + 16x4096 = 65,536 + 65,536 = 131,072
- 비율 : 131,072 / 16,777,216 = 0.0078125 (약 0.78%)
Base model 대비 학습되는 파라미터 수가 약 0.78%로 크게 줄었습니다.
(정확하게는 모든 Layer에 Adaptor(, )를 추가하는 것이 아니기 때문에 더 줄어듭니다.)
이렇게 LoRA를 사용하면 Base model의 성능은 어느정도 유지하면서 학습되는 파라미터 수를 크게 줄일 수 있습니다.
추가적으로, LoRA 기법으로 학습하기 위하여 Hyper 파라미터를 몇가지 설정해야 합니다.
이는 경험에 의존해야 하며 몇 가지 Tip을 적어봅니다.
- 일반적으로 r의 값은 16에서 시작하여 키우는 경우가 많습니다.
- epoch를 너무 크게 하면 over fitting 되기 쉬으므로 r, 알파값, dataset의 수 등을 고려하여 적절히 정해야 합니다.
- Training dataset의 Loss를 Saturation 될때까지 학습하면 over fitting 될 수 있습니다. Validation dataset의 Loss를 함께 체크하는 것이 좋습니다.
- Batch size는 너무 작지 않게 하는 것이 좋습니다. 메모리가 부족하면 Loss를 몇번 누적했다가 학습시키는 방법도 있습니다.